Information
Updated at best once per year, likely missing cool new stuff !
Anomaly detection and explanation
This project deals with unsupervised techniques for anomaly detection, attention focus mechanisms and clustering for anomaly explanation, as well as practical matters like streaming aggregation of distributed alarms and correct evaluation metrics for temporal anomaly detection.
Anomaly detection
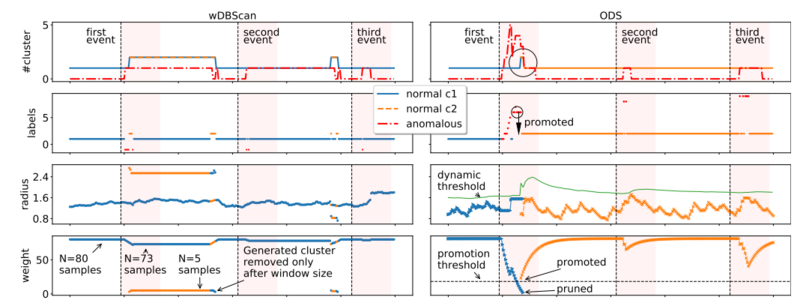
We design unsupervised algorithms that can work in batch mode, such as Random Histogram Forest (RHF), as well as in streaming mode such as Outlier Anomaly Detection DenStream (OADDS). We additionally devise ensemble techniques to automatically combine several algorithmic outputs for better performance at bounde cost.
Our techniques:
-
for batch mode, surpass state of the art Isolation Forest (IF) on most benchmarks [ICDM-20]
-
for stream mode, achieves results that are on par with the state of the art, i.e., the stream version of IF who is currently Robust Random Cut Forest (RRCF), while being 100x times faster [TNSM-20b] .
-
for ensembling, allows to seamlessly combine supervised and completely unsupervised ensembling schemes, protecting both data privacy and business sensitive information [PCT/FR2021/000024]
Additionally, we design bespoke metrics for the task of temporal anomaly detection that overcome limitations of classical metrics and cannot be gamed by trivial predictions [KDD-22].
To know more:
-
[AICCSA-22]
Nesic, Stefan and Putina, Andrian and Bahri, Maroua and Huet, Alexis and Navarro, Jose Manuel and Rossi, Dario and Sozio, Mauro,
"StreamRHF: Tree-based unsupervised anomaly detection for data streams"
19th ACS/IEEE International Conference on Computer Systems and Applications (AICCSA 2022)
dec.
2022,
Conference
@inproceedings{DR:AICCSA-22, title = {{StreamRHF: Tree-based unsupervised anomaly detection for data streams}}, author = {Nesic, Stefan and Putina, Andrian and Bahri, Maroua and Huet, Alexis and Navarro, Jose Manuel and Rossi, Dario and Sozio, Mauro}, year = {2022}, month = dec, booktitle = {19th ACS/IEEE International Conference on Computer Systems and Applications (AICCSA 2022)}, howpublished = {https://nonsns.github.io/paper/rossi22aiccsa.pdf}, note = {project=huawei}, topic = {ad-algo} }We present StreamRHF, an unsupervised anomaly detection algorithm for data streams. Our algorithm builds on some of the ideas of Random Histogram Forest (RHF), a state-of-the-art algorithm for batch unsupervised anomaly detection. StreamRHF constructs a forest of decision trees, where feature splits are determined according to the kurtosis score of every feature. It irrevocably assigns an anomaly score to data points, as soon as they arrive, by means of an incremental computation of its random trees and the kurtosis scores of the features. This allows efficient online scoring and concept drift detection altogether. Our approach is tree-based which boasts several appealing properties, such as explainability of the results. We conduct an extensive experimental evaluation on multiple datasets from different real-world applications. Our evaluation shows that our streaming algorithm achieves comparable average precision to RHF while outperforming state-of-the-art streaming approaches for unsupervised anomaly detection with furthermore limited computational complexity. -
[KDD-22]
Huet, Alexis and Navarro, Jose Manuel and Rossi, Dario,
"Local Evaluation of Time Series Anomaly Detection Algorithms"
ACM SIGKDD Conference on Knowledge Discovery and Data mining (KDD)
aug.
2022,
arXiv
Conference
@inproceedings{DR:KDD-22, title = {Local Evaluation of Time Series Anomaly Detection Algorithms}, author = {Huet, Alexis and Navarro, Jose Manuel and Rossi, Dario}, year = {2022}, month = aug, booktitle = {ACM SIGKDD Conference on Knowledge Discovery and Data mining (KDD)}, howpublished = {https://nonsns.github.io/paper/rossi22kdd.pdf}, arxiv = {https://arxiv.org/abs/2206.13167}, note = {project=huawei}, topic = {ad-algo} }In recent years, specific evaluation metrics for time series anomaly detection algorithms have been developed to handle the limitations of the classical precision and recall. However, such metrics are heuristically built as an aggregate of multiple desirable aspects, introduce parameters and wipe out the interpretability of the output. In this article, we first highlight the limitations of the classical precision/recall, as well as the main issues of the recent event-based metrics – for instance, we show that an adversary algorithm can reach high precision and recall on almost any dataset under weak assumption. To cope with the above problems, we propose a theoretically grounded, robust, parameter-free and interpretable extension to precision/recall metrics, based on the concept of “affiliation” between the ground truth and the prediction sets. Our metrics leverage measures of duration between ground truth and predictions, and have thus an intuitive interpretation. By further comparison against random sampling, we obtain a normalized precision/recall, quantifying how much a given set of results is better than a random baseline prediction. By construction, our approach keeps the evaluation local regarding ground truth events, enabling fine-grained visualization and interpretation of algorithmic results. We compare our proposal against various public time series anomaly detection datasets, algorithms and metrics. We further derive theoretical properties of the affiliation metrics that give explicit expectations about their behavior and ensure robustness against adversary strategies. -
[PATENT-PCT/FR2021/000024]
Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario and Putina, Andrian and Sozio, Mauro,
 "System and method for combining anomaly detection algorithms" , Patent PCT/FR2021/000024
2021,
Patent
"System and method for combining anomaly detection algorithms" , Patent PCT/FR2021/000024
2021,
Patent
@misc{DR:PATENT-PCT/FR2021/000024, author = {Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario and Putina, Andrian and Sozio, Mauro}, title = {System and method for combining anomaly detection algorithms}, topic = {ad-algo}, note = {Patent PCT/FR2021/000024}, patent = {True}, year = {2021} } -
[TNSM-20b]
Putina, Andrian and Rossi, Dario,
" Online anomaly detection leveraging stream-based clustering and real-time telemetry"
In IEEE Transactions on Network and Service Management,
Vol. 18,
No. 1,
pp.–,
nov.
2020,
DOI 110.1109/TNSM.2020.3037019
Journal
@article{DR:TNSM-20b, author = {Putina, Andrian and Rossi, Dario}, journal = {IEEE Transactions on Network and Service Management}, title = { Online anomaly detection leveraging stream-based clustering and real-time telemetry}, year = {2020}, month = nov, volume = {18}, number = {1}, pages = {--}, doi = {110.1109/TNSM.2020.3037019}, note = {keyword=anomaly, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20tnsm-b.pdf}, topic = {ad-algo} }Recent technology evolution allows network equipment to continuously stream a wealth of “telemetry” information, which pertains to multiple protocols and layers of the stack, at a very fine spatial-grain and high-frequency. This deluge of telemetry data clearly offers new opportunities for network control and troubleshooting, but also poses a serious challenge for what concerns its real-time processing. We tackle this challenge by applying streaming machine-learning techniques to the continuous flow of control and data-plane telemetry data, with the purpose of real-time detection of anomalies. In particular, we implement an anomaly detection engine that leverages DenStream, an unsupervised clustering technique, and apply it to features collected from a large-scale testbed comprising tens of routers traversed up to 3 Terabit/s worth of real application traffic. We contrast DenStream with offline algorithms such as DBScan and Local Outlier Factor (LOF), as well as online algorithms such as the windowed version of DBScan, ExactSTORM, Continuous Outlier Detection (COD) and Robust Random Cut Forest (RRCF). Our experimental campaign compares these seven algorithms under both accuracy and computational complexity viewpoints: results testify that DenStream (i) achieves detection results on par with RRCF, the best performing algorithm and (ii) is significantly faster than other approaches, notably over two orders of magnitude faster than RRCF. In spirit with the recent trend toward reproducibility of results, we make our code available as open source to the scientific community. -
[ICDM-20]
Putina, Andrian and Sozio, Mauro and Navarro, Jose M. and Rossi, Dario,
"Random Histogram Forest for Unsupervised Anomaly Detection"
20th IEEE International Conference on Data Mining (ICDM)
nov.
2020,
DOI
Conference
@inproceedings{DR:ICDM-20, author = {Putina, Andrian and Sozio, Mauro and Navarro, Jose M. and Rossi, Dario}, title = {Random Histogram Forest for Unsupervised Anomaly Detection}, booktitle = {20th IEEE International Conference on Data Mining (ICDM)}, month = nov, year = {2020}, volume = {}, pages = {}, doi = {}, note = {keyword=anomaly, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20icdm.pdf}, topic = {ad-algo} }Roughly speaking, anomaly detection consists of identifying instances whose features significantly deviate from the rest of input data. It is one of the most widely studied problems in unsupervised machine learning, boasting applications in network intrusion detection, fraud detection, healthcare and many others. Several methods have been developed in recent years, however, a satisfactory solution is still missing to the best of our knowledge. We present Random Histogram Forest an effective approach for unsupervised anomaly detection. Our approach is probabilistic, which has been proved to be effective in identifying anomalies. Moreover, it employs the fourth central moment (aka kurtosis), so as to identify potential anomalous instances. We conduct an extensive experimental evaluation on 38 datasets including all benchmarks for anomaly detection, as well as the most successful algorithms for unsupervised anomaly detection, to the best of our knowledge. Moreover, we provide some novel datasets that are made publicly available. We evaluate all the approaches in terms of the average precision of the area under the precision-recall curve (AP) as well as ROC. Our evaluation shows that our approach significantly outperforms all other approaches, both in terms of both AP and ROC, while boasting linear running time.
Anomaly explanation
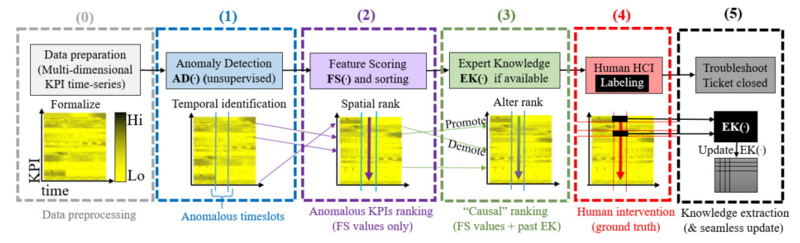
We design unsupervised techniques to explain anomalies intuitively to the network expert, in the original domain.
We complement these techniques with semi-supervised ones, that are able to learn from simple probabilistic representation of previous anomalies, and greatly assist the network troubleshooting task, even when an Oracle is used to perfectly solve the anomaly detection problem.
We exploit the results of the unsupervised techniques in order to build knowledge bases we call anomalyDBs, that allow experts to contextualize and classify the anomalous event they’re analyzing [ITC34].
Our techniques:
-
are incremental by design, hot swappable, and seamlessly accumulate knowledge without requiring direct human interaction [PCT/EP2020/05233][ITC32]
-
are able to compensate for practical performance of weak unsupervised anomaly detection algorithms [ComNet-22].
-
can lead to a reduction of more than 75% in median of the time needed by an expert to analyze an anomaly [ComNet-22].
To know more:
-
[ComNet-22]
Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario,
"Human readable network troubleshooting based on anomaly detection and feature scoring"
nov.
2022,
DOI https://doi.org/10.1016/j.comnet.2022.109447
arXiv
Tech.Rep.
@techreport{DR:ComNet-22, title = {Human readable network troubleshooting based on anomaly detection and feature scoring}, author = {Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario}, journal = {Elsevier Computer Networks}, month = nov, volume = {219}, year = {2022}, issn = {1389-1286}, topic = {ad-fs}, note = {project=huawei}, doi = {https://doi.org/10.1016/j.comnet.2022.109447}, arxiv = {https://arxiv.org/abs/2108.11807} }Network troubleshooting is still a heavily human-intensive process. To reduce the time spent by human operators in the diagnosis process, we present a system based on (i) unsupervised learning methods for detecting anomalies in the time domain, (ii) an attention mechanism to rank features in the feature space and finally (iii) an expert knowledge module able to seamlessly incorporate previously collected domain-knowledge. In this paper, we thoroughly evaluate the performance of the full system and of its individual building blocks: particularly, we consider (i) 10 anomaly detection algorithms as well as (ii) 10 attention mechanisms, that comprehensively represent the current state of the art in the respective fields. Leveraging a unique collection of expert-labeled datasets worth several months of real router telemetry data, we perform a thorough performance evaluation contrasting practical results in constrained stream-mode settings, with the results achievable by an ideal oracle in academic settings. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, and (ii) that even a simple statistical approach is able to extract useful information from expert knowledge gained in past cases, significantly improving troubleshooting performance. -
[ITC-22]
Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario,
"Rare Yet Popular: Evidence and Implications from Anomaly Detection Datasets"
International Teletraffic Congress (ITC34)
sep.
2022,
arXiv
Conference
@inproceedings{DR:ITC-22, title = {Rare Yet Popular: Evidence and Implications from Anomaly Detection Datasets}, author = {Navarro, Jose Manuel and Huet, Alexis and Rossi, Dario}, month = sep, year = {2022}, booktitle = {International Teletraffic Congress (ITC34)}, howpublished = {https://nonsns.github.io/paper/rossi22itc.pdf}, arxiv = {https://arxiv.org/abs/2211.10129}, note = {project=huawei}, topic = {ad-fs} }Anomaly detection research works generally propose algorithms or end-to-end systems that are designed to automatically discover outliers in a dataset or a stream. While literature abounds concerning algorithms or the definition of metrics for better evaluation, the quality of the ground truth against which they are evaluated is seldom questioned. On this paper, we present a systematic analysis of available public (and additionally our private) ground truth for anomaly detection in the context of network environment, where data is intrinsically temporal, multivariate and, in particular, exhibits spatial properties, which to the best of our knowledge we are the first to explore. Our analysis reveals that, while anomalies are by definition temporally rare events, their spatial characterization clearly shows some type of anomalies are significantly more popular than others. This can be achieved through surprisingly simple techniques and may have profound implications on the cost and quality of the labeling process. -
[ITC-20]
Navarro, Jose M. and Rossi, Dario,
"HURRA! Human readable router anomaly detection"
International Teletraffic Congress (ITC32)
sep.
2020,
DOI
Conference
Award
@inproceedings{DR:ITC-20, author = {Navarro, Jose M. and Rossi, Dario}, title = {HURRA! Human readable router anomaly detection}, booktitle = {International Teletraffic Congress (ITC32)}, month = sep, year = {2020}, volume = {}, pages = {}, doi = {}, note = {keyword=anomaly,bestpaperaward, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20itc.pdf}, topic = {ad-fs} }This paper presents HURRA, a system that aims to reduce the time spent by human operators in the process of network troubleshooting. To do so, it comprises two modules that are plugged after any anomaly detection algorithm: (i) a first attention mechanism, that ranks the present features in terms of their relation with the anomaly and (ii) a second module able to incorporates previous expert knowledge seamlessly, without any need of human interaction nor decisions. We show the efficacy of these simple processes on a collection of real router datasets obtained from tens of ISPs which exhibit a rich variety of anomalies and very heterogeneous set of KPIs, on which we gather manually annotated ground truth by the operator solving the troubleshooting ticket. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, that (ii) even a simple statistical approach is able to extracting useful information from expert knowledge gained in past cases to further improve performance and finally that (iii) the main difficulty in live deployment concerns the automated selection of the anomaly detection algorithm and the tuning of its hyper-parameters. -
[INFOCOM-20a]
Navarro, Jose Manuel and Rossi, Dario,
"HURRA: Human-Readable Router Anomaly Detection"
IEEE INFOCOM, Demo session
jul.
2020,
DOI
Conference
@inproceedings{DR:INFOCOM-20a, author = {Navarro, Jose Manuel and Rossi, Dario}, title = {HURRA: Human-Readable Router Anomaly Detection}, booktitle = {IEEE INFOCOM, Demo session}, month = jul, year = {2020}, volume = {}, pages = {}, doi = {}, note = {keyword=anomaly, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20infocom-a.pdf}, topic = {ad-fs} }Automated troubleshooting tools must be based on solid and principled algorithms to be useful. However, these tools need to be easily accessible for non-experts, thus requiring to also be usable. This demo combines both requirements by combining an anomaly detection engine inspired by Auto-ML principles, that combines multiple methods to find robust solutions, with automated ranking of results to provide an intuitive interface that is remindful of a search engine. The net result is that HURRA! simplifies as much as possible human operators interaction while providing them with the most useful results first. In the demo, we contrast manual labeling of individual features gathered from human operators from real troubleshooting tickets with results returned by the engine — showing an empirically good match at a fraction of the human labor.