Information
Updated at best once per year, likely missing cool new stuff !
Dynamic Radio Ressource Management
In this project we are developing methodologies and techniques for zero-touch autonomous network configuration. We design novel algorithms having practical relevance, that we deploy on real network.


At a glance
Channel allocation
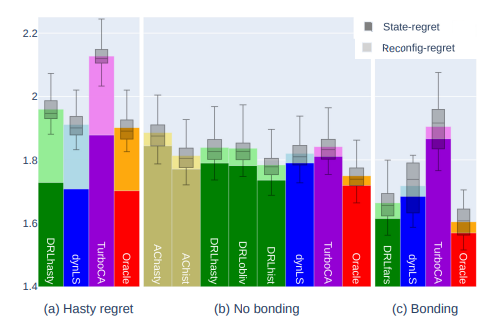
Leveraging AC data, we optimize AP channel and bondings settings, and contrast it to state of the art Cisco TurboCA in simulation [NETWORKING-21] and real deployment [COMMAG-22].
Power management
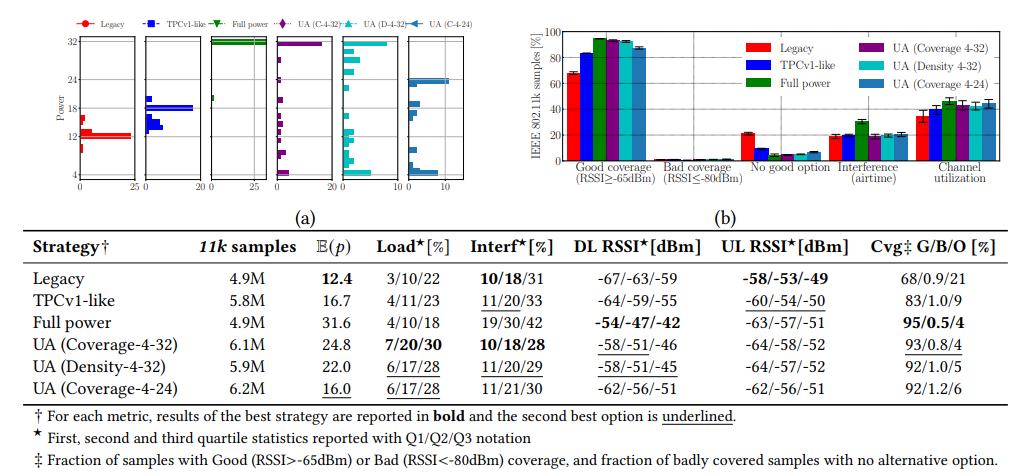
Leveraging IEEE 802.11k data, we optimize AP power settings and contrast it to state of the art Cisco TPCv1 [TECHREP-22-WLANpowerControl] in real deployment.
Transformer-based RRM
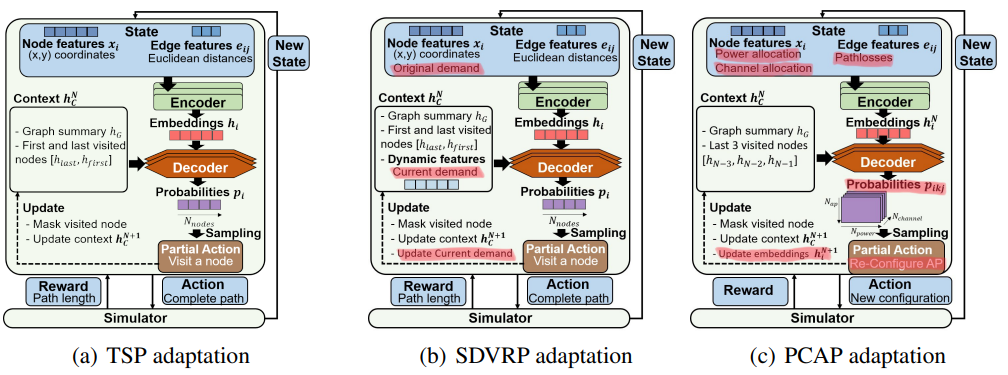
Leveraging progress in neural architectures, we explore transformer based architectures with self-attention mechanism [AAAI-22] for the purpose of (power and) channel allocation.
GNN-based inference
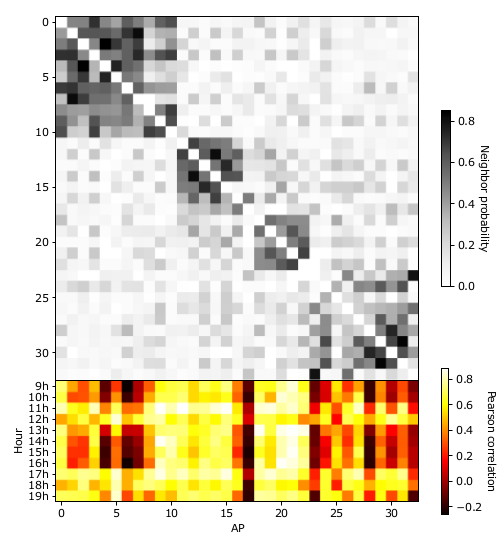
We contrast Graph Neural Networks with classical recurrent neural architecture for the purpose of estimating WLAN interference [CoNEXT-GNN-22] .
References
-
[COMMAG-23]
Iacoboaiea, Ovidiu and Krolikowski, Jonatan and Houidi, Zied Ben and Rossi, Dario,
"From Design to Deployment of Zero-touch Deep Reinforcement Learning WLANs"
In IEEE Communication Magazine,
Vol. 61,
feb.
2023,
DOI 10.1109/MCOM.002.2200318
arXiv
Journal
@article{DR:COMMAG-23, author = {Iacoboaiea, Ovidiu and Krolikowski, Jonatan and Houidi, Zied Ben and Rossi, Dario}, title = {From Design to Deployment of Zero-touch Deep Reinforcement Learning WLANs}, journal = {IEEE Communication Magazine}, arxiv = {https://arxiv.org/abs/2207.06172}, howpublished = {https://ieeexplore.ieee.org/document/9992177}, year = {2023}, topic = {wlan-algo}, month = feb, volume = {61}, issue = {2}, doi = {10.1109/MCOM.002.2200318} }Machine learning is increasingly used to automate networking tasks, in a paradigm known as zero touch network and service management (ZSM). In particular, deep reinforcement learning (DRL) techniques have recently gained much attention for their ability to learn taking complex decisions in different fields. In the ZSM context, DRL is an appealing candidate for tasks such as dynamic resource allocation, which are generally formulated as hard optimization problems. At the same time, successful training and deployment of DRL agents in realworld scenarios face a number of challenges that we outline and address in this article. Tackling the case of wireless local area network radio resource management, we report guidelines that extend to other use-cases and more general contexts. -
[PATENT-PCT/EP2023/050709]
KROLIKOWSKI, Jonatan and HOUIDI, Zied BEN and CHEN, Fuxing and ROSSI, Dario,
 "A data-driven WLAN topology-related KPIs query system and estimation method" , Patent PCT/EP2023/050709
jan.
2023,
Patent
"A data-driven WLAN topology-related KPIs query system and estimation method" , Patent PCT/EP2023/050709
jan.
2023,
Patent
@misc{DR:PATENT-PCT/EP2023/050709, author = {KROLIKOWSKI, Jonatan and HOUIDI, Zied BEN and CHEN, Fuxing and ROSSI, Dario}, title = {A data-driven WLAN topology-related KPIs query system and estimation method}, note = {Patent PCT/EP2023/050709}, month = jan, topic = {wlan}, patent = {True}, year = {2023} } -
[CoNEXT-GNN-22]
Fernandes, Danilo Marinho and Krolikowski, Jonatan and Houidi, Zied Ben and Chen, Fuxing and Rossi, Dario,
"Cross-network transferable neural models for WLAN interference estimation"
ACM CoNext workshop on Graph Neural Networks (GNN)
dec.
2022,
Conference
@inproceedings{DR:CoNEXT-GNN-22, title = {{Cross-network transferable neural models for WLAN interference estimation}}, author = {Fernandes, Danilo Marinho and Krolikowski, Jonatan and Houidi, Zied Ben and Chen, Fuxing and Rossi, Dario}, year = {2022}, month = dec, booktitle = {ACM CoNext workshop on Graph Neural Networks (GNN)}, topic = {wlan}, howpublished = {https://nonsns.github.io/paper/rossi22conext-gnn.pdf}, note = {project=huawei} }Airtime interference is a key performance indicator for WLANs, measuring, for a given time period, the percentage of time during which a node is forced to wait for other transmissions before to transmitting or receiving. Being able to accurately estimate interference resulting from a given state change (e.g., channel, bandwidth, power) would allow a better control of WLAN resources, assessing the impact of a given configuration before actually implementing it. In this paper, we adopt a principled approach to interference estimation in WLANs. We first use real data to characterize the factors that impact it, and derive a set of relevant synthetic workloads for a controlled comparison of various deep learning architectures in terms of accuracy, generalization and robustness to outlier data. We find, unsurprisingly, that Graph Convolutional Networks (GCNs) yield the best performance overall, leveraging the graph structure inherent to campus WLANs. We notice that, unlike e.g. LSTMs, they struggle to learn the behavior of specific nodes, unless given the node indexes in addition. We finally verify GCN model generalization capabilities, by applying trained models on operational deployments unseen at training time. -
[CommMag-22]
Iacoboaiea, Ovidiu and Krolikowski, Jonatan and Houidi, Zied Ben and Rossi, Dario,
"From Design to Deployment of Zero-touch Deep Reinforcement Learning WLANs"
In IEEE Communications Magazine (vol. to appear),
dec.
2022,
DOI 10.1109/MCOM.002.2200318
arXiv
Journal
@article{DR:CommMag-22, author = {Iacoboaiea, Ovidiu and Krolikowski, Jonatan and Houidi, Zied Ben and Rossi, Dario}, title = {From Design to Deployment of Zero-touch Deep Reinforcement Learning WLANs}, arxiv = {https://arxiv.org/abs/2207.06172}, journal = {IEEE Communications Magazine (vol. to appear)}, year = {2022}, month = dec, doi = {10.1109/MCOM.002.2200318}, howpublished = {/ai4net/docs/rossi22commag.pdf}, note = {project=huawei}, topic = {wlan} }Machine learning (ML) is increasingly used to automate networking tasks, in a paradigm known as zero-touch network and service management (ZSM). In particular, Deep Reinforcement Learning (DRL) techniques have recently gathered much attention for their ability to learn taking complex decisions in different fields. In the ZSM context, DRL is an appealing candidate for tasks such as dynamic resource allocation, that is generally formulated as hard optimization problems. At the same time, successful training and deployment of DRL agents in real-world scenarios faces a number of challenges that we outline and address in this paper. Tackling the case of Wireless Local Area Network (WLAN) radio resource management, we report guidelines that extend to other usecases and more general contexts. -
[AAAI-22]
Boffa, Matteo and Houidi, Zied Ben and Krolikowski, Jonatan and Rossi, Dario,
"Neural combinatorial optimization beyond the TSP: Existing architectures under-represent graph structure"
AAAI workshop on Graphs and more complex structures for learning and reasoning (GLCR’22)
2022,
arXiv
Conference
@inproceedings{DR:AAAI-22, title = {Neural combinatorial optimization beyond the TSP: Existing architectures under-represent graph structure}, author = {Boffa, Matteo and Houidi, Zied Ben and Krolikowski, Jonatan and Rossi, Dario}, year = {2022}, booktitle = { AAAI workshop on Graphs and more complex structures for learning and reasoning (GLCR'22)}, howpublished = {https://nonsns.github.io/paper/rossi22aaai-glcr.pdf}, arxiv = {https://arxiv.org/abs/2201.00668}, note = {project=huawei}, topic = {wlan} }Recent years have witnessed the promise that reinforcement learning, coupled with Graph Neural Network (GNN) architectures, could learn to solve hard combinatorial optimization problems: given raw input data and an evaluator to guide the process, the idea is to automatically learn a policy able to return feasible and high-quality outputs. Recent work have shown promising results but the latter were mainly evaluated on the travelling salesman problem (TSP) and similar abstract variants such as Split Delivery Vehicle Routing Problem (SDVRP). This paper assesses how and whether recent neural architectures also transfer to graph problems of practical interest. We thus set out to systematically transfer these architectures to the Power and Channel Allocation Problem (PCAP), which has practical relevance for, e.g., radio resource allocation in wireless networks. Our experimental results suggest that existing architectures (i) are still incapable of capturing graph structural features and (ii) are not suitable for problems where the actions on the graph change the graph attributes. On a positive note, we show that augmenting the structural representation of problems with Distance Encoding is a promising step towards the still-ambitious goal of learning multi-purpose autonomous solvers. -
[NETWORKING-21]
Iacoboaiea, Ovidiu and Krolikowski, Jonatan and Ben Houidi, Zied and Rossi, Dario,
"Real-Time Channel Management in WLANs: Deep Reinforcement Learning
Versus Heuristics"
IFIP Networking
jun.
2021,
Conference
@inproceedings{DR:NETWORKING-21, author = {Iacoboaiea, Ovidiu and Krolikowski, Jonatan and {Ben Houidi}, Zied and Rossi, Dario}, title = {{Real-Time} Channel Management in {WLANs:} Deep Reinforcement Learning Versus Heuristics}, booktitle = {IFIP Networking}, address = {Helsinki, Finland}, month = jun, year = {2021}, howpublished = {https://nonsns.github.io/paper/rossi21networking.pdf}, topic = {wlan}, note = {project=huawei} }Today’s WLANs rely on a centralized Access Controller (AC) entity for managing distributed wireless Access Points (APs) to which user devices connect. The availability of real-time analytics at the AC opens the possibility to automate the allocation of scarce radio resources, continuously adapting to changes in traffic demands. Often, the allocation problem is formulated in terms of weighted graph coloring, which is NP-hard, and custom heuristics are used to find satisfactory solutions. In this paper, we contrast solutions that are based on (and even improve) state of the art heuristics to a data-driven solution that leverages Deep Reinforcement Learning (DRL). Based on both simulation results as well as experiments in a real deployment, we show that our DRL-based scheme not only learns to solve the complex combinatorial problem in bounded time, outperforming heuristics, but it also exhibits appealing generalization properties, e.g. to different network sizes and densities. -
[INFOCOM-21]
Krolikowski, Jonatan and Iacoboaiea, Ovidiu and Houidi, Zied Ben and Rossi, Dario,
"WiFi Dynoscope: Interpretable Real-Time WLAN Optimization"
IEEE INFOCOM, Demo session
may.
2021,
DOI
Conference
@inproceedings{DR:INFOCOM-21, author = {Krolikowski, Jonatan and Iacoboaiea, Ovidiu and Houidi, Zied Ben and Rossi, Dario}, title = {WiFi Dynoscope: Interpretable Real-Time WLAN Optimization}, booktitle = {IEEE INFOCOM, Demo session}, month = may, year = {2021}, volume = {}, pages = {}, doi = {}, note = {project=huawei}, howpublished = {https://nonsns.github.io/paper/rossi21infocom.pdf}, topic = {wlan} }Today’s Wireless Local Area Networks (WLANs) rely on a centralized Access Controller (AC) entity for managing a fleet of Access Points (APs). Real-time analytics enable the AC to optimize the radio resource allocation (i.e. channels) on-line in response to sudden traffic shifts. Deep Reinforcement Learning (DRL) relieves the pressure of finding good optimization heuristics by learning a policy through interactions with the environment. However, it is not granted that DRL will behave well in unseen conditions. Tools such as the WiFi Dynoscope introduced here are necessary to gain this trust. In a nutshell, this demo dissects the dynamics of WLAN networks, both simulated and from real large-scale deployments, by (i) comparatively analyzing the performance of different algorithms on the same deployment at high level and (ii) getting low-level details and insights into algorithmic behaviour.