Error!
First public version dumped, likely some bugs ahead!
Traffic classification
This project tackles the fine-grained classification of Internet applications from encrypted traffic, by leveraging lightweight traffic properties, such as the size and direction of the first few packets of a flow. The project contains a training part (i.e., building models) as well as an inference part (i.e., making use of trained models), itself split into a algorithmic and system components.
Inference / Algorithmic
While classification of known traffic is a well investigated subject with supervised classification tools (such as ML and DL models) are known to provide satisfactory performance, detection of unknown (or zero-day) traffic is more challenging and typically handled by unsupervised techniques (such as clustering algorithms).
Our techniques:
-
for known traffic classification, our models outperforms state of the art academic evaluations (usually limited to few tens of classes, with hundreds thousands of weight per class) in commercial-grade settings (hundreds of classes, and hundreds thousands of weights overall) [TSNM-21]
-
for zero day detection, our novel gradient-based technique [PCT/EP2021/057212] is significantly more accurate and light-weight than the state of the art [ICML-UDL-21][COMMAG-21]

To know more:
-
[TNSM-21b]
Yang, Lixuan and Finamore, Alessandro and Feng, Jun and Rossi, Dario,
"Deep Learning and Zero-Day Traffic Classification: Lessons learned from a commercial-grade dataset"
In IEEE Transactions on Network and Service Management,
Vol. 18,
No. 4,
pp.4103–4118,
dec.
2021,
DOI 10.1109/TNSM.2021.3122940
arXiv
Journal
@article{DR:TNSM-21b, author = {{Yang}, Lixuan and {Finamore}, Alessandro and {Feng}, Jun and {Rossi}, Dario}, title = {Deep Learning and Zero-Day Traffic Classification: Lessons learned from a commercial-grade dataset}, journal = {IEEE Transactions on Network and Service Management}, volume = {18}, number = {4}, pages = {4103--4118}, year = {2021}, month = dec, doi = {10.1109/TNSM.2021.3122940}, note = {project=huawei}, arxiv = {https://arxiv.org/abs/2104.03182}, howpublished = {https://nonsns.github.io/paper/rossi21tnsm-b.pdf}, topic = {tc-algo} }The increasing success of Machine Learning (ML) and Deep Learning (DL) has recently re-sparked interest towards traffic classification. While supervised techniques provide satisfactory performance when classifying known traffic, the detection of zero-day (i.e., unknown) traffic is a more challenging task. At the same time, zero-day detection, generally tackled with unsupervised techniques such as clustering, received less coverage by the traffic classification literature which focuses more on deriving DL models via supervised techniques. Moreover, the combination of supervised and unsupervised techniques poses challenges not fully covered by the traffic classification literature. In this paper, we share our experience on a commercial-grade DL traffic classification engine that combines supervised and unsupervised techniques to identify known and zero-day traffic. In particular, we rely on a dataset with hundreds of very fine grained application labels, and perform a thorough assessment of two state of the art traffic classifiers in commercial-grade settings. This pushes the boundaries of traffic classifiers evaluation beyond the few tens of classes typically used in the literature. Our main contribution is the design and evaluation of GradBP, a novel technique for zero-day applications detection. Based on gradient backpropagation and tailored for DL models, GradBP yields superior performance with respect to state of the art alternatives, in both accuracy and computational cost. Overall, while ML and DL models are both equally able to provide excellent performance for the classification of known traffic, the non-linear feature extraction process of DL models backbone provides sizable advantages for the detection of unknown classes over classical ML models -
[ICML-UDL-21]
Yang, Lixuan and Rossi, Dario,
"Thinkback: Task Specific Out-of-Distribution Detection"
International Conference on Machine Learning (ICML) workshop on Uncertainty and Robustness in Deep Learning (UDL) 2021
jun.
2021,
Conference
@inproceedings{DR:ICML-UDL-21, author = {{Yang}, Lixuan and {Rossi}, Dario}, title = {Thinkback: Task Specific Out-of-Distribution Detection}, year = {2021}, month = jun, booktitle = {International Conference on Machine Learning (ICML) workshop on Uncertainty and Robustness in Deep Learning (UDL) 2021}, topic = {tc-algo}, note = {project=huawei}, howpublished = {https://nonsns.github.io/paper/rossi21icml-udl.pdf} }The increased success of Deep Learning (DL) has recently sparked large-scale deployment of DL models in many diverse industry segments. Yet, a crucial weakness of supervised model is the inherent difficulty in handling out-of-distribution samples, i.e., samples belonging to classes that were not presented to the model at training time. We propose in this paper a novel way to formulate the out-of-distribution detection problem, tailored for DL models. Our method does not require fine tuning process on training data, yet is significantly more accurate than the state of the art for out-ofdistribution detection. -
[NETMAG-21]
Yang, Lixuan and and Dario Rossi,
"Quality monitoring and assessment of deployed Deep Learning models for Network AIOps"
In IEEE Network Magazine,,
pp. 84-90,
nov.
2021,
DOI 10.1109/MNET.001.2100227
Journal
@article{DR:NETMAG-21, author = {{Yang}, Lixuan and and Dario {Rossi}}, title = {Quality monitoring and assessment of deployed Deep Learning models for Network AIOps}, journal = {IEEE Network Magazine,}, year = {2021}, month = nov, vol = {35}, issue = {6}, pages = { 84-90}, doi = {10.1109/MNET.001.2100227}, topic = {tc-algo}, note = {project=huawei}, howpublished = {https://nonsns.github.io/paper/rossi21netmag.pdf} }Artificial Intelligence (AI) has recently attracted a lot of attention, transitioning from research labs to a wide range of successful deployments in many fields, which is particularly true for Deep Learning (DL) techniques. Ultimately, DL models are software artifacts, that, as any software realization, need to be regularly maintained and updated: consequently, as a logical extension of the DevOps software development practices to AI-software applied to network operation and management, AIOps foresee to continuously push evolved models in production networks. While for some network use-cases DL models can be incrementally updated at relatively low cost, the more typical case is that updating deployed DL models has a significant cost that needs to be managed. It follows that, during the lifecycle of DL model deployment, it is important to assess the relative “staleness” of deployed DL models, so to prioritize update of “ageing” models. In this article, we cover the issue of quality assessment and tracking of DL models deployed for network management purposes.
Inference / System
In cooperation with the Net5.0/Measurement team, we have designed and implemented a prototype architecture for Fast In-network Analytics called FENXI [SEC-21]. The system introduces error-correcting approximate caching [PCT/EP2021/050902] and optimally leverages Ascend310 TPUs acceleration, by dynamically adapting the batch size to the traffic conditions, and to minimize query latency while maximizing processing throughput at the same time. With respect to operational points optimized for batch-processing such as GPU-based systems, FENXI is naturally fit for a bursty processing tied to traffic arrival process [SIGCOMM-20].
Overall, FENXI allows off-the-shelf hardware to perform advanced data-plane Deep Learning analytics at:
-
high-speed (100Gbps)
-
low-delay (below 10ms)
-
low-power consumption (on the order of few tens of Watts for the TPU)
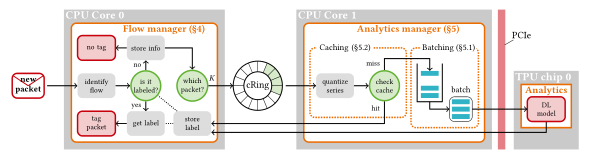
To know more:
-
[SIGCOMM-20]
Gallo, Massimo and Finamore, Alessandro and Simon, Gwendal and Rossi, Dario,
"Real-time Deep Learning based Traffic Analytics"
ACM SIGCOMM, Demo session
aug.
2020,
DOI
Conference
@inproceedings{DR:SIGCOMM-20, author = {Gallo, Massimo and Finamore, Alessandro and Simon, Gwendal and Rossi, Dario}, title = {Real-time Deep Learning based Traffic Analytics}, booktitle = {ACM SIGCOMM, Demo session}, month = aug, year = {2020}, volume = {}, pages = {}, doi = {}, note = {keyword=deeplearning,system,classification, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20sigcomm.pdf}, topic = {tc-system} }The increased interest towards Deep Learning (DL) tech-nologies has led to the development of a new generation of specialized hardware accelerator such as Graphic Processing Unit (GPU) and Tensor Processing Unit (TPU). The integration of such components in network routers is however not trivial. Indeed, routers typically aim to minimize the overhead of per-packet processing, and design choices to integrate a new accelerator need to factor in these key requirements. The literature and benchmarks on DL hardware accelerators have overlooked specific router constraints (e.g., strict latency) and focused instead on cloud deployment and image processing. Likewise,there is limited literature regarding DL application on traffic processing at line-rate. Among all hardware accelerators, we are interested in edge TPUs. Since their design focuses on DL inference, edge TPUs matches the vision of operators, who consider running pre-trained DL models in routers with low power drain. Edge TPUs are expected to limit the amount of computational resources for inference and to yield a higher ratio of operations-per-watt footprint than GPUs.This demo aims to investigate the operational points at which edge TPUs become a viable option, using traffic classification as a use case. We sketch the design of a real-time DL traffic classification system, and compare inference speed (i.e., number of classifications per second) of a state-of-the-art Convolutional Neural Network (CNN) model running on different hardware (CPU, GPU, TPU). To constrast their performance, we run stress tests based on synthetic traffic and under different conditions. We collect the results into a dashboard which enables network operators and system designers to both explore the stress test results with regards to their considered operational points, as well as triggering synthetic live tests on top of Ascend310 TPUs. -
[SEC-21]
Gallo, Massimo and Finamore, Alessandro and Simon, Gwendal and Rossi, Dario,
"FENXI: Fast In-Network Analytics"
IEEE/ACM Symposium on Edge Computing (SEC)
dec.
2021,
arXiv
Conference
@inproceedings{DR:SEC-21, author = {Gallo, Massimo and Finamore, Alessandro and Simon, Gwendal and Rossi, Dario}, title = {{FENXI}: Fast In-Network Analytics}, booktitle = {IEEE/ACM Symposium on Edge Computing (SEC)}, year = {2021}, month = dec, note = {project=huawei}, howpublished = {https://nonsns.github.io/paper/rossi21sec.pdf}, arxiv = {http://arxiv.org/abs/2105.11738}, topic = {tc-system} }Live traffic analysis at the first aggregation point in the ISP network enables the implementation of complex traffic engineering policies but is limited by the scarce processing capabilities, especially for Deep Learning (DL) based analytics. The introduction of specialized hardware accelerators i.e., Tensor Processing Unit (TPU), offers the opportunity to enhance processing capabilities of network devices at the edge. Yet, to date, no packet processing pipeline is capable of offering DL-based analysis capabilities in the data-plane, without interfering with network operations. In this paper, we present FENXI, a system to run complex analytics by leveraging TPU. The design of FENXI decouples forwarding operations and traffic analytics which operates at different granularities i.e., packet and flow levels. We conceive two independent modules that asynchronously communicate to exchange network data and analytics results, and design data structures to extract flow level statistics without impacting per-packet processing. We prototype FENXI on a general-purpose server and evaluate its performance in both adversarial and realistic network conditions. Our evaluation shows that FENXI is able to offer DL processing to 100 Gbps linecards with a limited number of resources, while also dynamically adapting to network conditions. -
[INFOCOM-22]
Finamore, Alessandro and Roberts, James and Gallo, Massimo and Rossi, Dario,
"Accelerating Deep Learning Classification with Error-controlled Approximate-key Caching"
IEEE INFOCOM
may.
2022,
arXiv
Conference
@inproceedings{DR:INFOCOM-22, title = {Accelerating Deep Learning Classification with Error-controlled Approximate-key Caching}, author = {Finamore, Alessandro and Roberts, James and Gallo, Massimo and Rossi, Dario}, booktitle = {IEEE INFOCOM}, year = {2022}, month = may, arxiv = {https://arxiv.org/abs/2112.06671}, howpublished = {https://nonsns.github.io/paper/rossi22infocom.pdf}, note = {project=huawei}, topic = {tc-system} }While Deep Learning (DL) technologies are a promising tool to solve networking problems that map to classification tasks, their computational complexity is still too high with respect to real-time traffic measurements requirements. To reduce the DL inference cost, we propose a novel caching paradigm, that we named approximate-key caching, which returns approximate results for lookups of selected input based on cached DL inference results. While approximate cache hits alleviate DL inference workload and increase the system throughput, they however introduce an approximation error. As such, we couple approximate-key caching with an error-correction principled algorithm, that we named auto-refresh. We analytically model our caching system performance for classic LRU and ideal caches, we perform a trace-driven evaluation of the expected performance, and we compare the benefits of our proposed approach with the state-of-the-art similarity caching – testifying the practical interest of our proposal.
Training
Model inference is possible only after a proper training phase: we have devised techniques for distributedly training classification models [IJCAIFL-20], [PCT/EP2020/061440], without the need for sharing training data, that are able to cope on multi-modal, skewed and even disjoint data distribution at clients. Additionally, we are working on incrementally training models, as soon as zero-day applications are discovered [TECHREP-21d].
Our techniques:
-
improves over Google FedAvg in terms of convergence speed, futher reducing the amount of weights to be shared [IJCAIFL-20], [PCT/EP2020/061440]
-
improve over the state of the art in incremental training [TMA-21]
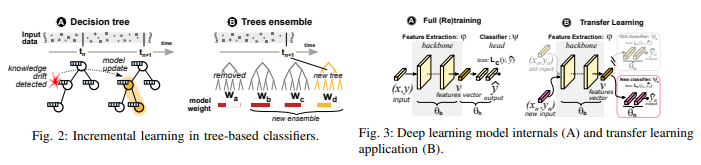
To know more:
-
[IJCAIFL-20]
Yang, Lixuan and Beliard, Cedric and Rossi, Dario,
"Heterogeneous Data-Aware Federated Learning"
International Joint Conference on Artificial Intelligence (IJCAI), Workshop on Federated Learning
sep.
2020,
DOI
Conference
@inproceedings{DR:IJCAIFL-20, author = {Yang, Lixuan and Beliard, Cedric and Rossi, Dario}, title = {Heterogeneous Data-Aware Federated Learning}, booktitle = {International Joint Conference on Artificial Intelligence (IJCAI), Workshop on Federated Learning}, month = sep, year = {2020}, volume = {}, pages = {}, doi = {}, note = {keyword=deeplearning, project=huawei}, howpublished = {https://perso.telecom-paristech.fr/drossi/paper/rossi20ijcai-fl.pdf}, topic = {tc-train} }Federated learning (FL) is an appealing concept to perform distributed training of Neural Networks (NN) while keeping data private. With the industrialization of the FL framework, we identify several problems hampering its successful deployment, such as presence of non i.i.d data, disjoint classes, signal multi-modality across datasets. In this work, we address these problems by proposing a novel method that not only (1) aggregates generic model parameters (e.g. a common set of task generic NN layers) on server (e.g. in traditional FL), but also (2) keeps a set of parameters (e.g, a set of task specific NN layer) specific to each client. We validate our method on the traditionally used public benchmarks (e.g., Femnist) as well as on our proprietary collected dataset (i.e., traffic classification). Results show the benefit of our method, with significant advantage on extreme cases. -
[TMA-21]
Bovenzi, Giampaolo and Yang, Lixuan and Finamore, Alessandro and Aceto, Giuseppe and Ciuonzo, Domenico and Pescape, Antonio and Rossi, Dario,
" A First Look at Class Incremental Learning in Deep Learning Mobile Traffic"
IFIP Traffic Monitoring and Analysis (TMA)
sep.
2021,
Conference
@inproceedings{DR:TMA-21, author = {Bovenzi, Giampaolo and Yang, Lixuan and Finamore, Alessandro and Aceto, Giuseppe and Ciuonzo, Domenico and Pescape, Antonio and Rossi, Dario}, title = { A First Look at Class Incremental Learning in Deep Learning Mobile Traffic}, booktitle = {IFIP Traffic Monitoring and Analysis (TMA)}, year = {2021}, month = sep, note = {project=huawei}, howpublished = {https://nonsns.github.io/paper/rossi21tma.pdf}, topic = {tc-train} }The recent popularity growth of Deep Learning (DL) re-ignited the interest towards traffic classification, with several studies demonstrating the accuracy of DL-based classifiers to identify Internet applications’ traffic. Even with the aid of hardware accelerators (GPUs, TPUs), DL model training remains expensive, and limits the ability to operate frequent model updates necessary to fit to the ever evolving nature of Internet traffic, and mobile traffic in particular. To address this pain point, in this work we explore Incremental Learning (IL) techniques to add new classes to models without a full retraining, hence speeding up model’s updates cycle. We consider iCarl, a state of the art IL method, and MIRAGE-2019, a public dataset with traffic from 40 Android apps, aiming to understand if there is a case for incremental learning in traffic classification. By dissecting iCarl internals, we discuss ways to improve its design, contributing a revised version, namely iCarl+. Despite our analysis reveals their infancy, IL techniques are a promising research area on the roadmap towards automated DL-based traffic analysis systems. -
[SIGCOMM-CCR-22]
Wang, Chao and Finamore, Alessandro and Yang, Lixuan and Fauvel, Kevin and Rossi, Dario,
"AppClassNet: A commercial-grade dataset for application identification research"
In ACM SIGCOMM Computer Communication Review,
Vol. 52,
jul.
2022,
DOI https://doi.org/10.1145/3561954.3561958
Journal
@article{DR:SIGCOMM-CCR-22, title = {{AppClassNet: A commercial-grade dataset for application identification research}}, author = {Wang, Chao and Finamore, Alessandro and Yang, Lixuan and Fauvel, Kevin and Rossi, Dario}, year = {2022}, journal = {ACM SIGCOMM Computer Communication Review}, month = jul, volume = {52}, issue = {3}, howpublished = {https://nonsns.github.io/paper/rossi22ccr.pdf}, doi = {https://doi.org/10.1145/3561954.3561958}, note = {project=huawei}, topic = {tc-train} }The recent success of Artificial Intelligence (AI) is rooted into several concomitant factors, namely theoretical progress coupled with abundance of data and computing power. Large companies can take advantage of a deluge of data, typically withhold from the research community due to privacy or business sensitivity concerns, and this is particularly true for networking data. Therefore, the lack of high quality data is often recognized as one of the main factors currently limiting networking research from fully leveraging AI methodologies potential. Following numerous requests we received from the scientific community, we release AppClassNet, a commercial-grade dataset for benchmarking traffic classification and management methodologies. AppClassNet is significantly larger than the datasets generally available to the academic community in terms of both the number of samples and classes, and reaches scales similar to the popular ImageNet dataset commonly used in computer vision literature. To avoid leaking user- and business-sensitive information, we opportunely anonymized the dataset, while empirically showing that it still represents a relevant benchmark for algorithmic research. In this paper, we describe the public dataset and our anonymization process. We hope that AppClassNet can be instrumental for other researchers to address more complex commercial-grade problems in the broad field of traffic classification and management.